Of IPTables, Netfilter Connection Tracking, and Fanout Servers
We use HAProxy for load balancing and Varnish as a caching HTTP reverse proxy in quite a few places. While these are two different technologies that serve two different purposes, they’re both types of “fanout” servers, meaning a client connects on the frontend and their request is routed to one of many backends.
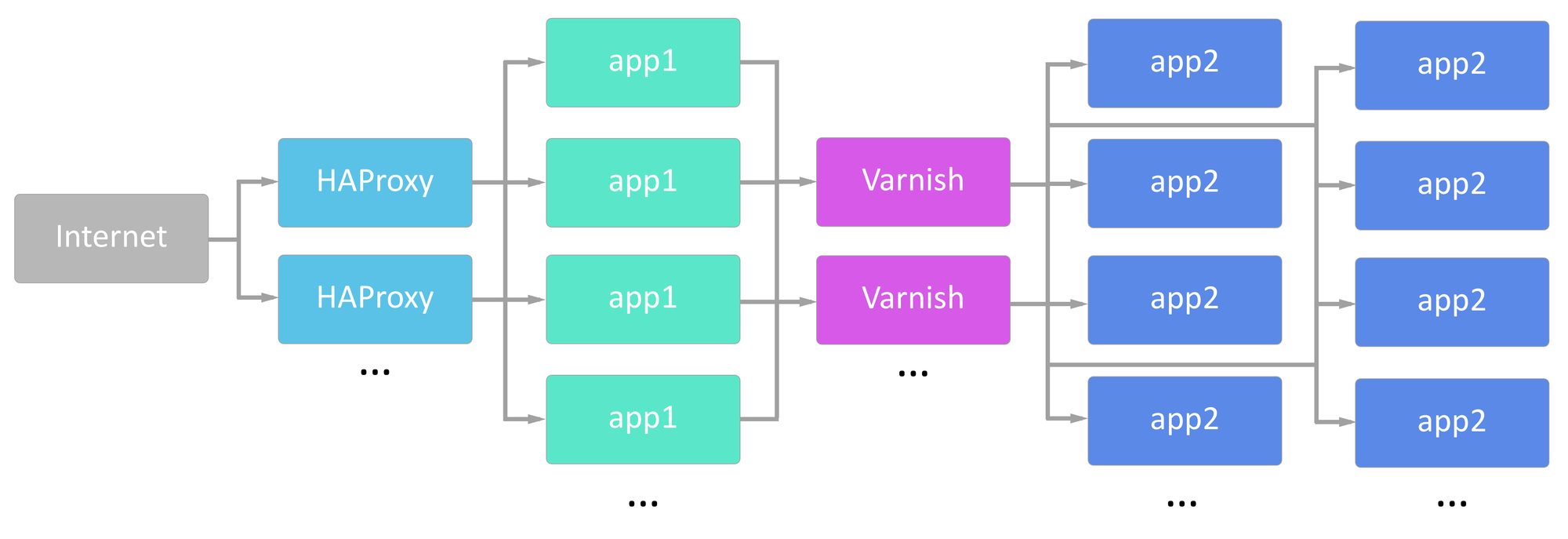
In our environment, we are routinely handling 20,000 connections per second and frequently bursting past 30,000 connections per second. One of our most common use cases is serving up an image and then tearing down the connection.
DDoS or Gremlins?
A while back, we had an issue where we were seeing mysterious timeouts and dropped connections from the Internet to the HAProxy layer. Our initial working theory was that we were experiencing some DDoS attack because this issue was occurring against a piece of infrastructure that had been rock solid for a significant amount of time. However, analysis of our logs argued firmly against the DDoS theory. We then formulated and investigated multiple hypotheses for what could be causing these issues ranging from application configuration to operating system tuning to network bandwidth limitations.
Definitely Gremlins
Similarly to losing a set of keys, the thing you’re looking for is always in the last place you look for it. After chasing down several rabbit holes, we finally noticed that dmesg on the HAProxy machines logged quite a few entries with nf_conntrack: table full, dropping packet. In addition to access control at the edge of our network, we run local firewalls on every machine to ensure that only the intended ports are exposed. IPTables provides a modular architecture to make it flexible. One of the modules in use by default is the Netfilter Connection Tracking module.
Connection Tracking
Netfilter’s Connection Tracking System is a module that provides stateful packet inspection for iptables. The key word in the last sentence is stateful. Any stateful system must maintain its state somewhere. In the case of nf_conntrack, that state is tracked in a hash table to provide efficient lookups. Like almost anything else in a Linux system, the hash table is configurable via two sysctl values, nf_conntrack_buckets and nf_conntrack_max. Per the kernel documentation nf_conntrack_buckets determines the number of buckets in the hash table, and nf_conntrack_max determines the maximum number of nodes in hash table. These two values directly impact the amount of memory required to maintain the table and the performance of the table. The memory required for the table is nf_conntrack_max * 304 bytes (each conntrack node is 304 bytes), and each bucket will contain nf_conntrack_max / nf_conntrack_buckets nodes.
Honing in on a solution
After quite a bit of googling, tweaking, load testing, and trial and error, we arrived at a set of configuration changes that signficantly increased the capacity of each of our HAProxy and Varnish systems. As it turns out, our priority is extremely heavily weighted toward maximizing the number of connections each “fanout” server is able to handle. This meant that nf_conntrack in any form was a major bottleneck for us. In the end, we opted to forego stateful packet inspection at the load balancer layer and disable nf_conntrack entirely. We blacklist the nf_conntrack and nf_nat via /etc/modprobe.d/blacklist-conntrack.conf:
blacklist nf_conntrack
install nf_conntrack /bin/true
blacklist nf_nat
install nf_nat /bin/true
Rinse and repeat
When you have a new favorite hammer, everything starts to look like a nail. Once we resolved the bottleneck at the top of our stack, the issue shifted further down to the Varnish layer. Fortunately, we were able to use the experiences from our HAProxy layer to identify and resolve the issue far more quickly.